EUC-KR을 확장한 한글 문자 인코딩
이전 글에서 소개한 바와 같이, EUC-KR은 자주 사용하는 2,350자 외의 한글 문자는 모두 생략해버린 문제가 있었습니다. 결국 EUC-KR이 포함하지 못한 한글 문자들을 표현하기 위한 문자 인코딩 방식이 다양하게 등장하였습니다. 그러나 그 중에서도 국내 가장 널리 보급된 것은 바로 코드페이지 949, 흔히 CP949로 줄여서 부르는 인코딩 방식입니다.
CP949는 Microsoft에서 Windows 95에 처음 도입하였던 인코딩으로, 도입 당시에는 Windows에서만 사용되었기 때문에 반발이 많았습니다. 그러나 이후 Windows가 한국의 OS 시장을 장악하면서 현재는 거의 EUC-KR을 대체한 상태입니다. 심지어 대부분의 웹 브라우저에서 EUC-KR로 표시된 인코딩 옵션은 사실은 CP949 인코딩을 가리킵니다.
CP949는 확장완성형(UHC, Unified Hangul Codeset)이라는 또다른 이름을 가지고 있습니다. 완성형인 EUC-KR에서 표현하지 못했던 글자까지 인코딩 영역을 확장했다는 의미로 보입니다. 2가지의 이름은 보통 비슷한 빈도로 섞여서 사용되고 있습니다.

CP949 Map (출처:위키피디아)
CP949는 기본적으로 EUC-KR을 그대로 가져온 후, EUC-KR에서 사용하지 않았던 영역에 EUC-KR에서 빠져있던 8,822글자를 가나다 순으로 채워넣은 방식입니다. CP949에서 추가된 영역은 2바이트를 연달아 사용하는데, 다음의 3가지 규칙에 따라서 배정되었습니다.
① 첫 번째 바이트는 0x81~0xC6 사이를 사용합니다.
② 두 번째 바이트는 0x41~0x5A, 0x61~0x7A, 0x81~0xFE의 총 3개 구간을 사용합니다.
③ 단, 첫 번째 바이트가 0xA1 이상인 경우에는, 두 번째 바이트는 0xA1 미만까지만 사용합니다.
③번 규칙이 만들어진 이유는, 첫 번째 바이트가 0xA1 이상이면서 두 번째 바이트도 0xA1 이상인 영역은 이미 EUC-KR에서 사용하고 있기 때문입니다. 그러나 사실 말이 규칙이지, EUC-KR이 표현하지 못한 글자들을 남은 자리에 임기응변으로 끼워넣었다는 인상이 강합니다.
위 3가지 규칙을 적용하면 CP949가 확장한 영역은 크게 3개 영역으로 나뉘어집니다. 첫 번째 영역은 [0x81~0xA0][0x41~0x5A, 0x61~0x7A, 0x81~0xFE], 두 번째 영역은 [0xA1~0xC5][0x41~0x5A, 0x61~0x7A, 0x81~0xA0], 세 번째 영역은 [0xC6][0x41~0x52]가 됩니다. 이 영역은 위키피디아에서 참조한 위 그림에도 표시되어 있습니다.
CP949 Table을 통해 확인하는 숫자와 문자와의 관계
앞서 살펴본 ASCII Table이나 EUC-KR Table과 마찬가지로, CP949 Table 역시 존재합니다. 어떤 문자의 16진수 값을 찾아보는 방법은 앞서의 두 Table과 동일하지만, CP949는 규칙이 복잡한만큼 문자 코드표를 5개 장으로 분류하고 있습니다.
이 중에서 3개 장은 EUC-KR과 동일한 코드표입니다. 2350 Hangul Syllables는 EUC-KR에서 한글이 배정되었던 영역을 그대로 다루고 있고, 특수문자를 대상으로 하는 Special Symbols과 한자를 담고 있는 Chinese Characters 역시 EUC-KR과 동일합니다.
CP949에서 추가된 영역은 Additional Hangul Syllable Set라고 표시되어 있는데, Additional Hangul Syllable Set 1이 첫 번째 바이트가 0xA1보다 작은 영역, Additional Hangul Syllable Set 2이 첫 번째 바이트가 0xA1 이상인 영역을 보여주고 있습니다. 이 영역을 살펴보고 있으면 ‘갂’, ‘닑’, ‘뢞’ 등과 같이 평소에는 볼 수 없는 한글 문자들이 배정되어 있는 것을 볼 수 있습니다.
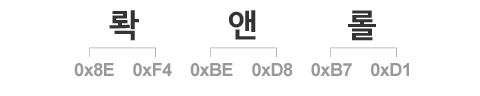 어떤 문자가 CP949에서 16진수로 어떻게 표시되는지 찾는 방법은, EUC-KR Table에서 이를 찾는 방법과 완벽하게 같습니다. 단지 EUC-KR에는 없던 글자들이 추가되었을 뿐입니다. 이를테면 위와 같은 “롹앤롤”이라는 단어를 EUC-KR로 표시하게 되면, 첫 번째 글자인 ‘롹’에 해당하는 16진수 값이 없어 단어가 깨지게 됩니다. 그러나 CP949 Table에는 이 글자가 [0x8E 0xF4]에 배정되어 있어 표현이 가능합니다.
어떤 문자가 CP949에서 16진수로 어떻게 표시되는지 찾는 방법은, EUC-KR Table에서 이를 찾는 방법과 완벽하게 같습니다. 단지 EUC-KR에는 없던 글자들이 추가되었을 뿐입니다. 이를테면 위와 같은 “롹앤롤”이라는 단어를 EUC-KR로 표시하게 되면, 첫 번째 글자인 ‘롹’에 해당하는 16진수 값이 없어 단어가 깨지게 됩니다. 그러나 CP949 Table에는 이 글자가 [0x8E 0xF4]에 배정되어 있어 표현이 가능합니다.
$str = "\x8E\xF4\xBE\xD8\xB7\xD1"; echo $str; // 롹앤롤
PHP 상에서 이것을 확인해보는 방법도 EUC-KR과 같습니다. 메타 태그에서는 EUC-KR로 되어 있는 점이 의아할 수는 있습니다만, 앞서 소개하였듯이 대부분의 웹브라우저는 겉으로는 EUC-KR라는 이름을 보여주고 있지만 내부적으로는 CP949 인코딩을 사용하고 있습니다. 심지어 Microsoft와 전혀 관련 없는 제 아이폰의 사파리 브라우저에서도 “롹앤롤”이라고 하는 단어가 잘 보입니다.
CP949 문자열과 정규표현식
CP949는 EUC-KR을 기본으로 위에서 소개한 3개 영역이 더 추가된 형태입니다. 따라서 이 3개 영역에 관한 정규표현식만 잘 표현하면 CP949 문자열을 처리하는 함수를 만들 수 있습니다. 그 예제로서 이 글에서 소개할 함수는, 주어진 문자열에서 CP949에서 확장된 한글문자 만을 찾아 HTML Entity Number로 변환하는 함수입니다.
(이러한 함수를 사용해야 하는 일은 드물지만 그렇다고 전혀 없는 것은 아닙니다. 대표적인 경우는 바로 MySQL에 Insert를 할 때입니다. MySQL에서 CP949 인코딩을 지원한 것은 5.1.38 버전부터입니다. 때문에 그보다 오래된 버전의 MySQL을 사용한다면 CP949 문자를 HTML Entity Number로 변환해야만 합니다. 그렇지 않으면 MySQL은 해당 필드에서 CP949 문자 이후의 값을 무시하고 Insert를 해버립니다.)
자, 여러분이 위 함수를 작성하신다면 어떻게 하시겠습니까. 제가 작성한 함수는 아래와 같습니다.
function convUHC2Euckr($s)
{
$r = '';
$p = 0;
$l = strlen($s);
$ex1 = '[\x81-\xA0][\x41-\x5A\x61-\x7A\x81-\xFE]';
$ex2 = '[\xA1-\xC5][\x41-\x5A\x61-\x7A\x81-\xA0]';
$ex3 = '[\xC6][\x41-\x52]';
$ex = '/^(' . $ex1 . ')|(' . $ex2 . ')|(' . $ex3 . ')/';
while($p < $l)
{
if(preg_match('/^[\x00-\x7F]/', $s, $m))
{
$m = $m[0];
$d = 1;
}
elseif(preg_match('/^[\xA1-\xFE][\xA1-\xFE]/', $s, $m))
{
$m = $m[0];
$d = 2;
}
elseif(preg_match($ex, $s, $m))
{
$m = mb_convert_encoding($m[0], 'HTML-ENTITIES', 'CP949');
$d = 2;
}
$r .= $m;
$p += $d;
$s = substr($s, $d);
}
return $r;
}
함수의 내용은 간단합니다. 앞에서부터 문자열을 잘라가며, 가장 앞의 2바이트가 CP949의 추가 한글영역에 해당하는지 정규표현식으로 검사합니다. 만약 그렇다면 mb_convert_encoding() 함수를 통해 해당 문자를 HTML Entity Number로 변환합니다.
이 글에서는 가로 스크롤 없이 코드를 볼 수 있도록 CP949 3개 영역을 검사하는 정규표현식을 각각 따로 작성하고 ‘|’로 묶었습니다. 실무에서 사용하실 때에는 그대로 1개의 문자열로 타이핑을 하시면 됩니다.
CP949의 약점 #1 : 문자열 처리가 까다롭다
그런데 위 함수를 보면 반복문 안에서 계속하여 문자열 연산이 이루어나기 때문에, 효율이 썩 좋아보이지 않습니다. 때문에 혹시 위 함수를 아래처럼 작성하면 되지 않을까 생각하는 분들도 분명히 계실 것입니다. 아래와 같이 preg_match_all() 함수를 사용하면, 정규표현식으로 주어진 영역에 해당하는 문자를 한번에 가져올 수 있으므로 문자열 연산을 할 필요도 없을 테니까요!
function convUHC2Euckr($s)
{
$ex1 = '[\x81-\xA0][\x41-\x5A\x61-\x7A\x81-\xFE]';
$ex2 = '[\xA1-\xC5][\x41-\x5A\x61-\x7A\x81-\xA0]';
$ex3 = '[\xC6][\x41-\x52]';
$ex = '/(' . $ex1 . ')|(' . $ex2 . ')|(' . $ex3 . ')/';
preg_match_all($ex, $s, $m);
foreach($m[0] as $v)
{
$h = mb_convert_encoding($v, 'HTML-ENTITIES', 'CP949');
$s = str_replace($v, $h, $s);
}
return $s;
}
convUHC2Euckr('쵝오A'); // 쵝�퓾
하지만 이 함수를 실제로 사용해보면 예기치 못한 오류가 발생하는 문자열이 존재합니다. 이를테면 “쵝오A”라는 문자열에 위 함수를 사용해보면, 우리는 CP949의 추가 한글영역에 해당하는 ‘쵝’자만 변환되기를 기대합니다. 그러나 현실은 “쵝�퓾”라고 하는 정체불명의 문자열이 반환됩니다.
이유가 무엇일까요. 여기서 CP949의 첫 번째 약점이 드러납니다. 사실 “쵝오A”라는 문자를 CP949 인코딩에서 16진수로 풀어보면 아래와 같습니다.
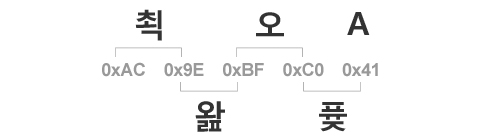 위 참고 이미지에서 보시는 바와 같이, 이 문자열은 첫 번째 바이트부터 정상적으로 읽었을 때는 “쵝오A”라고 표기가 되지만, 중간부터 읽으면 전혀 다른 글자가 나타나는 걸 볼 수 있습니다. ‘쵝’의 2번째 바이트인 0x9E와 ‘오’의 1번째 바이트인 0xBF를 합친 [0x9E 0xBF]를 CP949 Table에서 찾아보면 ‘왎’이라는 글자에 해당합니다. 마찬가지로 ‘오’의 2번째 바이트인 0xC0와 알파벳 ‘A’의 ASCII 코드인 0x41을 합한 [0xC0 0x41]을 찾아보면 ‘퓾’이라는 글자에 해당합니다.
위 참고 이미지에서 보시는 바와 같이, 이 문자열은 첫 번째 바이트부터 정상적으로 읽었을 때는 “쵝오A”라고 표기가 되지만, 중간부터 읽으면 전혀 다른 글자가 나타나는 걸 볼 수 있습니다. ‘쵝’의 2번째 바이트인 0x9E와 ‘오’의 1번째 바이트인 0xBF를 합친 [0x9E 0xBF]를 CP949 Table에서 찾아보면 ‘왎’이라는 글자에 해당합니다. 마찬가지로 ‘오’의 2번째 바이트인 0xC0와 알파벳 ‘A’의 ASCII 코드인 0x41을 합한 [0xC0 0x41]을 찾아보면 ‘퓾’이라는 글자에 해당합니다.
따라서 위 코드에서 preg_match_all() 함수를 사용하고 나면, $m에는 ‘쵝’에 해당하는 [0xAC 0x9E] 뿐만 아니라, ‘왎’에 해당하는 [0x9E 0xBF]와 ‘퓾’에 해당하는 [0xC0 0x41]까지 총 3개가 검출되어 들어오게 됩니다. 따라서 우리가 의도하지 않았던 문자들이 HTML Entity Number로 변환되겠지요.
EUC-KR은 첫 번째 비트가 0인 영역은 무조건 ASCII 코드와 동일하게, 두 번째 비트가 1인 영역은 무조건 두 바이트씩 묶어서 한글로 사용한다는 철칙이 있어 혼란이 없었습니다. 그러나 CP949는 이 규칙이 무너지면서, 어떤 바이트를 이전 바이트와 묶어 한 글자로 보느냐 다음 바이트와 묶어 한 글자로 보느냐에 따라 결과가 달라지는 경우가 발생합니다. 때문에 CP949 문자열은 가장 앞 바이트부터 차례차례 읽지 않고는 정상적으로 처리되기 어렵고, 오류로 인해 중간에 몇 바이트가 소실되면 해당 바이트 이후의 문서를 정상적으로 읽을 수 없게 됩니다.
CP949의 약점 #2 : 가나다순 정렬의 문제
sort() 함수는 배열 안의 요소들을 순서대로 정렬할 수 있는 편리한 함수입니다. 그러나 아래 코드를 실행하면 그 환상은 깨어질지도 모르겠습니다. 아래 코드를 실행한 후 $arr의 문자들은 우리가 기대했던 가나다순이 아닌 “롹뷁기푱차” 순서대로 정렬이 됩니다.
$arr = array('가', '롹', '뷁', '차', '푱');
sort($arr); // 롹 뷁 가 푱 차
sort() 함수는 기본적으로 배열 안의 요소들을 16진수 값 순서대로 정렬합니다. 그런데 CP949는 EUC-KR이 사용하지 않는 영역에 확장된 한글문자들을 그대로 끼워넣었기 때문에, 16진수 값 순서가 가나다순과는 완전히 다릅니다. 가나다순이라면 가장 먼저 나와야 할 ‘가’는 CP949에서는 0xB0A1입니다. 그러나 CP949에서 확장된 글자인 ‘롹’은 0x8EF4, ‘뷁’은 0x94EE로, ‘가’보다 16진수 상으로 훨씬 앞에 등장합니다. 이것은 ‘푱(0xBE79)’과 ‘차(0xCEF7)’에서도 동일하게 나타나는 현상입니다.
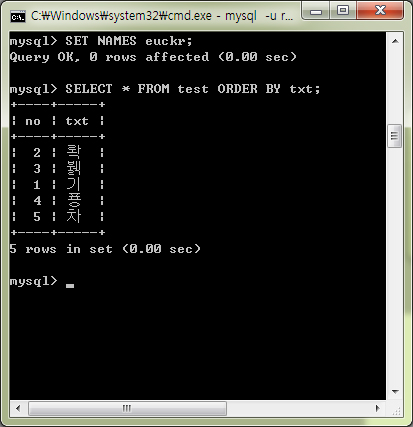
sort() 함수 뿐만 아니라, 이 문제는 MySQL에서도 동일하게 나타납니다. 앞서 소개하였듯이 MySQL도 최근 버전은 CP949 문자 입력이 가능한데, 그렇다 하여도 이 정렬문제까지 해결된 것은 아닙니다. 위처럼 실제 테이블에 예제에서 보았던 다섯 문자를 Insert하고 order by 문을 이용해 Select를 해보면, 동일한 문제가 발생하는 것을 확인할 수 있습니다. 원인은 앞서 살펴본 바와 같습니다.
이 같은 약점으로 인해 CP949가 처음 등장하였을 때에는 많은 거부감을 불러 일으켰고 실제로 반대하는 움직임이 있기도 하였습니다. 그러나 현재에는 되돌이킬 수 없을 정도로 CP949가 널리 보급되었기 때문에 역으로 MS 계열이 아닌 브라우저나 OS에서도 CP949를 지원하기에 이르렀습니다. 그러나 시장상황을 돌이킬 수 없다 하더라도, 개발자라면 분명 이 인코딩 방식의 약점과 그 원인은 알고 있어야 할 것입니다.
우와 감사합니다. 정말 찾던 거였어요 대단하시네요
이렇게 답글까지 남겨주셔서 제 쪽에서 오히려 감사말씀 드립니다. 🙂 앞으로도 좋은 글로 찾아뵙겠습니다.
안녕하세요?
은행연합회 전각문자를 cp949로 변경해야 하는데요.
db는 테라데이터를 사용하고 있습니다.
변환하려면 어떤 방법이 있을까요?
제가 생각하는 방법은 구글링 해보니 c나 자바로
변환하는 소스가 있는데 그걸 udf로 구현하면 되지 않을까
싶습니다만 보다 쉽게 널리 쓰이는 방법을 혹시
알고 계신지 해서 여쭙니다.
좋은 하루되세요.
안녕하세요. 먼저 일천한 블로그에 관심가져주셔서 감사드립니다.
말씀하셨던 바와 같이 소스코드 레벨에서 쿼리결과를 변환하는 안이 가장 손쉽게 떠올릴 수 있는 방법이라고 생각이 됩니다. 다만 그에 앞서 DBMS 또는 드라이버 수준에서 원하는 인코딩으로 쿼리결과를 얻을 수 있는지 검토해보시면 어떨까요.
이를테면 MySQL의 경우에는 접속시에 캐릭터셋을 정하면 해당 Connection에서는 원천 데이터의 캐릭터셋이 무엇이든 접속시 설정한 캐릭터셋으로 쿼리결과가 반환됩니다. 사용하시는 DBMS인 테라데이터는 제가 경험은 없습니다만, 도큐멘테이션을 참조하시거나 기술지원을 받으실 수 있다면 알아보실 수 있지 않을런지요. 혹시라도 이러한 검토를 이미 마친 상태이시라면, 부족한 제 생각을 용서해주시기 바랍니다.
좋은자료 감사히 읽었습니다.
문자 인코딩에 대해서 이렇게 자세하고 알기 쉽게 설명해 놓으시다니..
제 주변에 누구도 이 정도로 명쾌하고 정확하게 답변해주시는 분이 없었는데.
덕분에 확실하게 배우고 갑니다.
좋은 지식을 배우게 해주셔서 감사합니다
eleccubic님, 방문해주시고 글 남겨주셔서 감사합니다. 머리 속에 담아두기에는 워낙에 복잡한 내용이다보니, 글을 쓴 저도 다 기억하지 못하고 수시로 제가 쓴 글을 찾아보곤 한답니다! 앞으로도 이 내용이 필요하실 때마다 자주 찾아주세요. 앞으로도 좋은 내용으로 또 만나뵙겠습니다.
저도 신입때 이 부분때문에 열심히 구글링 했던 기억이 떠오르네요.
#1~3 모두 잘 보았습니다. 깔끔한 정리능력이 부럽네요^^
혹시 중국어에 대한 부분도 알고 계신지 여쭤봅니다.
이너님 반갑습니다. 저도 실무에서 중국어 코드를 다뤄볼 기회는 만나보지 못해서 실은 잘 알지 못핮니다. 다만 도움이 될만한 아티클을 하나 찾았는데 참고해보시면 어떨런지요.
http://aknot.tistory.com/m/49
좋은 내용 공유해주셔서 감사합니다.
gggaaaa님, 오래된 글임에도 덧글 남겨주셔서 감사합니다. 더 가치있는 내용 공유할 수 있게 노력하겠습니다.