유니코드의 값을 그대로 사용한 UTF-32
앞서 살펴본 UCS-2는 기본 다국어 평면 만을 이용하여 2바이트로 깔끔하게 떨어지는 인코딩 방식을 만들어냈지만, 나머지 평면을 표시할 수 없는 문제가 있었습니다. UTF-32는 이와 정확하게 반대의 방법으로 만들어진 인코딩입니다. UTF-32는 유니코드의 모든 문자를 표현할 수 있도록 한 글자당 32비트를 사용하는 인코딩입니다.
UTF-32는 유니코드를 알고 있는 사람들은 무척 심플하다고 생각할 수 있는 규칙을 가지고 있습니다. UTF-32에서 앞의 2바이트는 [0x00 0x00]부터 [0x00 0x10]까지 몇 번째 평면인가를 표시합니다. 또한 뒤의 2바이트는 UCS-2가 그랬던 것처럼 해당 평면의 어느 문자인지를 나타냅니다.
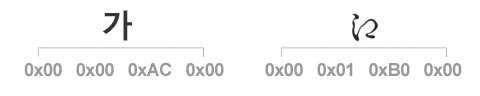
이를테면 계속하여 예로 들고있는 한글 “가”는 0번 기본 다국어 평면의 0xAC00 자리에 배정되어 있습니다. 따라서 한글 “가”를 UTF-32로 표현하면, 0번 평면이기 때문에 앞의 2바이트는 [0x00 0x00], 해당 평면의 0xAC00 자리이기 때문에 뒤의 2바이트는 [0xAC 0x00]으로 표시하면 됩니다. 한편 유니코드 편에서 살펴보았던 옛 히라가나 ![]() 는 1번 보조 다국어 평면의 0xB000 자리에 있으므로, UTF-32에서는 [0x00 0x01 0xB0 0x00]이 됩니다.
는 1번 보조 다국어 평면의 0xB000 자리에 있으므로, UTF-32에서는 [0x00 0x01 0xB0 0x00]이 됩니다.
UTF-32는 유니코드를 그대로 4바이트 자리에 가져다 넣은 것이기 때문에 유니코드와 서로 비교하기 쉽습니다. 또한 한 글자가 차지하는 크기가 4바이트로 고정되어 있기 때문에 문자열 처리가 간결해지는 장점이 있습니다. 과거편에서 우리가 살펴본 EUC-KR이나 CP949는 알파벳은 1바이트, 한글은 2바이트로 경우에 따라 한 글자가 차지하는 크기가 달라졌지요.
UTF-32와 UCS-4와의 관계
UTF-32는 UCS-4라고도 불립니다. 32비트는 바이트로 환산하면 4바이트에 해당하기 때문에 붙여진 별명이라고 단순히 생각하기 쉽지만, 사실은 좀더 복잡한 사정이 있습니다. 엄밀하게 UCS-4는 문자집합으로서 정해진 표준이고, UTF-32는 그 UCS-4를 인코딩으로 사용하기 위해 정해진 규칙입니다.
하지만 UTF-32는 현재의 UCS-4를 그대로 사용하기로 규칙을 정했기 때문에, 현재는 UCS-4와 UTF-32가 완벽하게 동일합니다. 그러나 UCS-4는 아직 표준이 확정된 것이 아니며, 추후에 더 많은 문자들이 추가될 가능성이 있습니다. 반면에 UTF-32는 현재 상태로 최종확정된 상태입니다. 따라서 UCS-4에 추후 더 많은 문자가 추가되면 UTF-32와 UCS-4는 더이상 같은 이름으로 사용되지 않게 되겠지요.
UTF-32의 2가지 단점
UTF-32도 역시 단점이 존재합니다.
첫 번째는 크기의 문제입니다. UTF-32는 한 글자가 고정적으로 4바이트를 차지하기 때문에, UTF-32로 저장한 문서는 빠르게 크기가 커지는 단점이 있습니다. 이 점은 한 글자에 1바이트를 사용하는 ASCII 코드와 비교해보면 분명합니다. 알파벳으로만 작성된 텍스트 파일을 저장할 때 UTF-32 인코딩을 사용한다면, ASCII 코드로 저장했을 때보다 4배 더 커지게 되겠지요.
두 번째 단점은 UTF-32 역시 CP949와 같은 이유로 문자열 처리가 까다롭다는 점입니다. 실제 사례를 살펴보면 간단하게 알 수 있습니다. 아래는 UTF-32로 한글 “가”와 옛 히라가나 ![]() 를 이어서 작성한 문자열입니다.
를 이어서 작성한 문자열입니다.
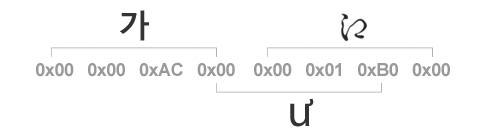
이 문자열을 4번째 바이트부터 읽으면, 0번 평면의 0x01B0 자리의 글자로 해석할 수도 있게 됩니다. 유니코드 테이블에서 해당 자리를 찾아보면 실제로 라틴 문자인 ư가 위치하고 있는 것을 확인할 수 있습니다. 이러한 이유로 UTF-32 역시 3편에서 살펴본 CP949와 마찬가지로, 문자열 중 몇 바이트가 유실되거나 중간 바이트부터 읽었을 때 정상적으로 문자열 처리를 할 수 없습니다.
HTML5에서는 잠정적으로 사용금지
마지막으로 UTF-32는 HTML5에서는 사용이 금지될 것으로 보입니다. 다음 편에서 살펴볼 인코딩인 UTF-16과 구분할 수 없기 때문이라고 합니다. 이 내용은 HTML5.1 사양 4.2.5.5 챕터에 아래와 같이 명시되어 있습니다.
Authors should not use UTF-32, as the encoding detection algorithms described in this specification intentionally do not distinguish it from UTF-16.
저작자는 UTF-32를 사용해서는 안된다. 본 사양에서 서술한 인코딩 감지 알고리즘은 UTF-32를 UTF-16과 의도적으로 구분하지 않기 때문이다.
하지만 실제로 우리가 UTF-32 인코딩을 사용할 일은 거의 없고, 실제로 지원하는 에디터 역시 많지 않습니다. 따라서 UTF-32에 관한 내용은 기반지식 정도로 삼고 가도 무방할 것입니다. 다음 편에서는 OS와 JAVA 등 훨씬 널리 사용되는 UTF-16에 관한 내용으로 이어갑니다.