문자별 인코딩의 한계
앞서 소개한 EUC-KR과 그 확장판인 CP949는 오직 한글 만을 위하여 만들어진 인코딩이었습니다. 그러나 컴퓨터를 사용하는 국가는 한국 만이 아닐 것입니다. 일본에서도 중국에서도, 우즈베키스탄과 인도에서도 컴퓨터는 사용되니, 그곳 문자들을 표시할 수 있는 인코딩이 매번 필요했을 것입니다.
이것은 각국의 문자 인코딩이 통일되지 못한 규칙을 가지고 만들어지는 결과를 낳았습니다. 문제는 이러한 인코딩으로 작성된 문서를 다른 인코딩으로 열어보면 읽을 수가 없다는 것입니다. 이를테면 EUC-KR 인코딩으로 “小數”라고 작성하고 저장한 텍스트 파일을, 일본에서 가장 널리쓰이는 인코딩 중 하나인 Shift-JIS로 열어보면 “盖筥”라는 전혀 다른 글자가 표시됩니다.
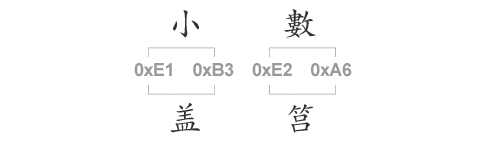
이유는 위와 같습니다. EUC-KR에서는 16진수 [0xE1 0xB3]를 “小”자에, [0xE2 0xA6]를 “數”자로 쓰고 있습니다. 그런데 같은 16진수 숫자쌍을 Shift-JIS에서는 “盖”자와 “筥”로 쓰고 있는 것입니다. 가끔 웹 브라우저로 일본어나 중국어로 작성된 웹 페이지에 들어갔을 때, 마구 깨어진 한글로 나오는 경우가 있습니다. 이것은 바로 일본어 또는 중국어 인코딩으로 쓰여진 글자들을, 웹 브라우저에서 한글 인코딩으로 읽어버렸기 때문입니다.
여기에 같은 16진수 숫자쌍을 서로 다른 글자로 쓰고 있다보니, 이러한 인코딩들로는 2개 이상의 언어를 섞어서 문서를 작성하는 것도 불가능합니다.
유니코드의 등장
앞서 살펴본 문제들을 풀기 위한 해결책은 간단합니다. 전세계의 문자를 통일된 규칙으로 정리하면 되는 것입니다. 그리하여 IBM, Microsoft, Apple과 같은 굵직굵직한 기업들과 수많은 개발자들이 통일된 규칙을 만들기 위해 머리를 맞대기 시작했습니다. 그 결과 1990년, 전세계의 모든 문자에 0x0000부터 0xFFFF까지 216개(65,536개)의 숫자를 매겨놓은 Unicode(유니코드)가 탄생하였습니다.
처음에 유니코드를 정할 때는 65,536개 정도의 자리면 전세계 모든 문자에 숫자를 매기기에 충분하다고 생각했습니다. 그러나 웬걸, 동아시아에는 한자라고 하는 무지막지한 문자가 존재했던 것입니다. 65,536개의 자리 중 반 이상을 한자에 배정하고 나니, 고대문자 등을 위한 자리가 남아있지 않았습니다.
결국 유니코드는 0x0000부터 0xFFFF까지 문자를 배정해놓은 세트를 총 17개로 늘리기로 합니다. 이 세트를 유니코드에서는 “평면(plain)”이라고 부르고, 앞에서부터 0번부터 16번까지 번호를 붙여놓았습니다. 또한 이 가운데에서 3번부터 13번까지의 11개 평면은 사용하지 않고 미래를 위하여 비워놓았습니다. 따라서 현재 사용되고 있는 평면은 0~2번과 14~16번의 6개 평면입니다.
이 평면들 중에서도 특별히 지금 우리 시대에 전세계에서 쓰이고 있는 문자들은 모두 0번 평면에 몰아넣어 놓았는데, 이 첫 번째 평면을 기본 다국어 평면(BMP, Basic multilingual plane)이라고 부릅니다. 이를테면 한글 “가”는 유니코드에서는 기본 다국어 평면 0xAC00에 배정되어 있습니다. 같은 원리대로 일본어 히라가나 “あ”는 기본 다국어 평면의 0x3042에 배정되어 있습니다.

Roadmap to Unicode BMP (출처:위키피디아)
물론 나머지 평면에도 각각의 이름이 있습니다. 이를테면 1번 평면은 보조 다국어 평면(SMP, Supplementary Multilingual Plane), 2번 평면은 보조 상형 문자 평면(SIP, Supplementary Ideographic Plane)이라고 부릅니다. 이 이름은 위키피디아의 유니코드 항목에서 모두 다루고 있으니 이쪽을 참고하시면 좋겠습니다.
유니코드를 표시하는 방법 : U+
그러나 평면이 여러 개가 되면 문제가 생깁니다. 모든 평면이 0x0000부터 0xFFFF까지의 값을 가지고 있으니, 하나의 16진수 숫자가 유니코드 상에서 어느 평면에 속하는지 애매해진 것입니다. 이를테면 0xB000는 0번 기본 다국어 평면에서는 한글 “뀀“자가 되는데, 1번 보조 다국어 평면에서는 일본의 옛 히라가나 글자인 ![]() 라는 글자를 의미하게 됩니다. 이렇게 되면 0xB000라는 16진수 숫자 만으로는 어느 글자인지 알 수가 없겠지요.
라는 글자를 의미하게 됩니다. 이렇게 되면 0xB000라는 16진수 숫자 만으로는 어느 글자인지 알 수가 없겠지요.
이러한 혼란을 방지하기 위해, 유니코드는 좀더 특별한 방법으로 표기를 합니다. 바로 기존의 4자리 16진수 숫자 앞에 평면 번호를 16진수로 붙이고, 이것이 유니코드라는 의미에서 “U+”라는 기호를 붙이는 것입니다. 단, 0번 기본 다국어 평면 만은 예외로 아무런 숫자를 앞에 붙이지 않습니다.
이 규칙을 따라서 문자를 표시해보면, 앞서 한글 “뀀”자는 0번 기본 다국어 평면에 있으니 아무 것도 붙이지 않고 U+B000라고 표시하면 됩니다. 한편 옛 히라가나 ![]() 는 1번 보조 다국어 평면에 있으니 1을 붙여 U+1B000라고 표시하면 되겠지요. 같은 규칙에 따라서 14번 평면에 속한 0xB000 문자는 14를 16진수로 표시한 E를 붙여 U+EB000라고 표시하며, 16번 마지막 평면에 속한 0xB000 문자는 U+10B000라고 표시하면 될 것입니다.
는 1번 보조 다국어 평면에 있으니 1을 붙여 U+1B000라고 표시하면 되겠지요. 같은 규칙에 따라서 14번 평면에 속한 0xB000 문자는 14를 16진수로 표시한 E를 붙여 U+EB000라고 표시하며, 16번 마지막 평면에 속한 0xB000 문자는 U+10B000라고 표시하면 될 것입니다.
유니코드 Table을 통해 확인하는 숫자와 문자와의 관계
그동안의 인코딩들은 1바이트 또는 2바이트에 불과하여, 표로 깔끔하게 정리할 수 있는 정도의 양이었습니다. 그러나 유니코드는 일단 평면 하나가 65,536개의 문자로 되어 있고, 그나마도 그 평면이 여러 개이기 때문에 더이상 하나의 표로 표시하는 것은 어렵습니다.
보통 유니코드의 어떤 16진수 숫자가 어떤 문자에 해당하는지를 찾을 때에는, 잘 정리된 웹 사이트들을 이용합니다. 단순히 열람을 위해서는 http://www.utf8-chartable.de/라는 독일 사이트가 UI는 투박하지만 잘 정리되어 있습니다. 그러나 검색 기능은 준비되지 않았기 때문에, 특정 글자가 유니코드로 어떤 숫자인지 찾을 때 제가 즐겨 방문하는 곳은 http://www.isthisthingon.org/unicode/입니다.
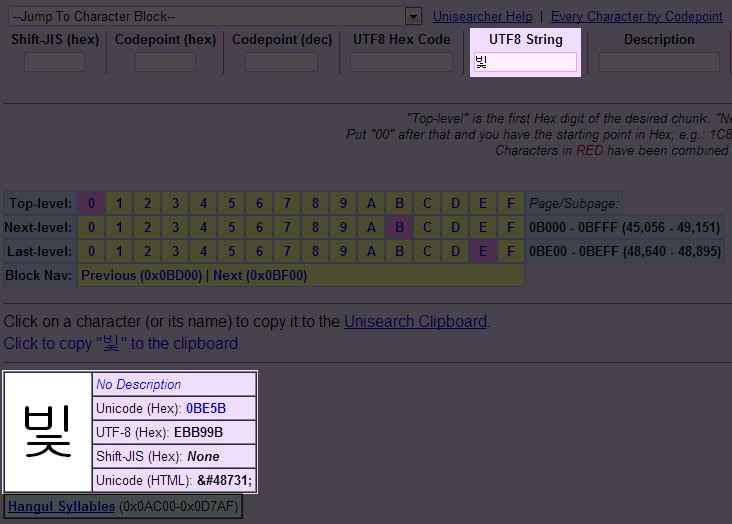
이를테면 한글 “빛”이라는 글자가 유니코드로 어떤 글자인지를 찾아보기 위해서는, 상단의 UTF8 String이라는 빈칸에 “빛”을 입력하고 검색을 하면 됩니다. 검색 후 화면에는 해당 글자의 유니코드 코드 값이 표시가 됩니다. 빛은 0BE5B로, 앞서 살펴본 표기에 따라서 써보면 U+BE5B가 될 것입니다.
마지막으로 이렇게 찾은 문자들은 때때로 서체에서 지원을 해주지 않아, 덩그러니 정사각형으로 깨어진 듯이 보일 때가 있습니다. http://www.fileformat.info/info/unicode/char/search.htm에서는 이러한 유니코드의 여러 문자들의 원형을 이미지 파일로 보여주고 있습니다. 검색창에서 유니코드 값을 타이핑해서 검색하는 방법으로 이용할 수 있습니다.
유니코드를 위한 새로운 인코딩들
그런데 이렇게 규칙을 정하고 나니 유니코드 그 자체로는 문자 인코딩으로 쓰기 까다로운 상황이 됩니다. 첫 번째로 평면을 표시하는 숫자를 가장 앞에 붙이고 나니, 처음의 2바이트 외에 애매하게 앞에 자리가 더 필요한 상황이 됩니다. 여기에 CP949 편에서 보았듯이 문자 인코딩은 특정 글자를 중간 바이트부터 읽었을 때, 다른 글자로 해석되지 않도록 할 필요가 있습니다.
이러한 문제를 해결하기 위해서 유니코드를 위한 많은 인코딩 방법들이 파생되어 나옵니다. 그 중에서 웹 개발자로서 직접적으로 지식을 갖추어야 할 인코딩으로는 UCS-2와 UTF-8이 있습니다. 또한 주로 JAVA나 OS에서 사용되기는 하나 UTF-8의 근간이 되기 때문에 알아야 하는 UTF-32와 UTF-16가 있습니다. 다음 편부터는 차례로 UCS-2, UTF-32와 UTF-16, UTF-8 순서대로 다룰 예정입니다.
읽기 쉽게 정리해주셔서 감사합니다.
방문자님, 소중한 덧글 감사합니다. 더 좋은 글로 계속하여 찾아 뵙겠습니다.