ASCII와의 호환성을 확보한 UTF-8
이전 편에서 소개한 UTF-16은 서러게이트를 활용한 방법으로 문자열이 잘못되었을 때 쉽게 파악할 수 있으면서도, 동시에 기본 다국어 평면 안의 문자를 2바이트 만으로 표현할 수 있는 효율성도 갖추었습니다. 그러나 UTF-16에는 아쉬운 부분이 바로 ASCII와의 호환성입니다.
ASCII에는 전통적으로 전산처리에서 특별한 기능을 하는 문자들이 있습니다. 이를테면 C언어를 비롯해 많은 언어에서 문자열이 끝났음을 의미하는 NULL 문자(U+0000), 줄바꿈에 사용되는 개행문자(U+000A), 띄어쓰기 등에 사용하는 공백문자(U+0020) 등이 그것입니다. 그런데 UTF-16에서는 문자 중간에 이들 문자의 ASCII 값이 섞여 들어가는 일이 발생합니다.
이를테면 고대 에게문명의 문자 가운데 “Aegean Number Eight Hundred”라는 문자가 있습니다. 동그라미 8개로 되어 있는 직관적인 문자인데, 유니코드에서는 U+10120가 배정되어 있습니다. 이 문자를 UTF-16으로 표현해보면 아래와 같습니다. 확인해보시면 ASCII에서 NULL 문자로 사용하는 [0x00]과 공백문자로 사용하는 [0x20]이 문자 사이에 섞여있게 되지요.
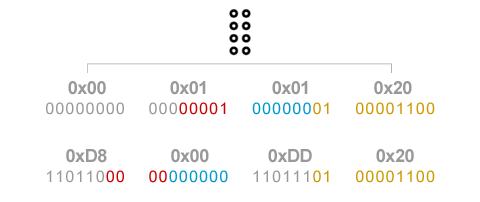
이 때문에 과거 ASCII를 흔히 사용하였던 때에 작성하였던 문서는 UTF-16으로는 그대로 읽어올 수가 없습니다. 결국 ASCII로의 하위호환성을 확보한 문자 인코딩이 등장하는데, 바로 지금부터 소개할 UTF-8입니다. 그 규칙은 크게 4가지 영역으로 구분되는데, 규칙이 적용되는 영역에 따라 16진수 자리수가 다르다는 것이 특징입니다.
ASCII에 해당하는 영역은 ASCII 코드와 동일하게 1바이트로

먼저 ASCII와 같은 영역에 해당하는 U+0000 ~ U+007F는 ASCII 코드와 동일하게 1바이트의 값을 그대로 사용합니다. 이를테면 물결표 ~는 유니코드에서는 U+007E에 해당하는데, UTF-8에서는 ASCII 코드와 동일하게 [0x37]로 표시하게 될 것입니다.
또 한가지 주목할 것은 이 영역에 있는 문자는 그 값을 2진수로 나타내보면 첫 번째 자리가 항상 0이라는 것입니다. ASCII 코드의 특징 중 하나인데, UTF-8에서도 이 특징은 동일하게 이어집니다. 따라서 ASCII 코드에 해당하는 영역과의 혼동을 피하려면, 이 영역을 제외한 다른 영역의 문자들은 2진수 첫 번째 자리가 0이 되어서는 안되겠지요.
하지만 U+0080부터는 그대로 16진수 값 [0x80]로 쓰면 2진수로 나타냈을 때 첫 번째 자리가 1이 되어버리고 맙니다. 그러므로 U+0080 이후로는 또다른 규칙이 필요합니다.
U+0080부터 U+07FF까지는 2바이트로
UTF-8에서는 먼저 U+0080 ~ U+07FF의 문자들을 2바이트를 사용하여 표현하는데, 이 규칙을 이해하기 위해서는 먼저 문자의 유니코드 값을 그대로 2진수로 표현해볼 필요가 있습니다. 이 값을 2진수로 표시해보면 하나같이 첫 번째 바이트의 앞의 5자리는 항상 0임을 확인할 수 있습니다.
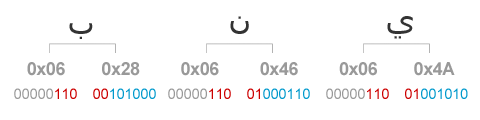
이를테면 아랍어로 갈색을 뜻하는 형용사 “بني”는 유니코드로 U+0628, U+0646, U+064A에 해당하는 3개의 문자로 이루어져 있습니다. 이들은 모두 U+0080 ~ U+07FF 영역 안에 있는 문자인데, 확인해보니 역시나 가장 앞의 5자리는 모두 0이군요. 이제 2진수 값을 아래와 같이 3개 부분으로 나누어 놓습니다.
① 1번째 바이트의 앞에서부터 5비트 … 항상 0이므로 버리는 부분
② 1번째 바이트의 뒤에서부터 3비트와 2번째 바이트의 앞에서부터 2비트 … ⓐ부분
③ 2번째 바이트의 뒤에서부터 6비트 … ⓑ부분
이렇게 ⓐ, ⓑ의 2개 부분을 정리하고 나면, 우리는 UTF-8 인코딩 값을 만들어낼 수 있습니다. 규칙은 간단합니다. 가장 앞에 110을 붙이고, ⓐ부분의 5자리를 이어 붙여 첫 번째 바이트를 만들어 냅니다. 다음으로 가장 앞에 10을 붙이고, ⓑ부분의 6자리를 이어 붙여 두 번째 바이트를 만들어내면 됩니다. 이렇게 만들어진 2바이트의 값이 바로 UTF-8 인코딩 값입니다.

이와 같이 우리는 “بني”의 UTF-8 문자코드를 얻을 수 있었습니다.
하지만 [0x08 0xFF]부터는 첫 번째 바이트의 앞의 4자리까지만 0이 되고, 5번째 비트에 1이 들어가게 됩니다. 이렇게 되면 더이상 위의 규칙을 사용할 수 없게 되겠지요. 이 때문에 UTF-8은 U+08FF부터의 문자들에 대해서는 다시 새로운 규칙을 적용하여 3바이트를 사용하게 됩니다.
U+0800부터 U+FFFF까지는 3바이트로
U+0800 ~ U+FFFF의 문자들에 적용되는 새로운 규칙은, 앞서의 규칙과 매우 유사합니다. 이 규칙을 설명하기 위하여 제물포라는 단어를 예제로 삼아봅시다. 유니코드에서 한글은 U+AC00 ~ U+D7AF 영역에 배정이 되어 있기 때문에, UTF-8에서 한글은 모두 이 규칙을 적용받습니다.
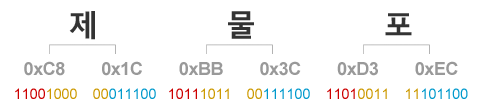
출발점은 앞서와 동일합니다. 먼저 유니코드 값을 2진수로 먼저 표현한 다음, 비트들을 3개 부분으로 쪼개는 것으로 시작합니다. 다만 이전 규칙과는 쪼개는 자리수가 조금 다르며, 버리는 부분도 없습니다.
① 1번째 바이트의 앞에서부터 4비트 … ⓐ부분
② 1번째 바이트의 뒤에서부터 4비트와 2번째 바이트의 앞에서부터 2비트 … ⓑ부분
③ 2번째 바이트의 뒤에서부터 6비트 … ⓒ부분
이렇게 ⓐ, ⓑ, ⓒ의 2개 부분을 정리하고 나면, 다음 규칙을 통해 3바이트의 값을 만들어내면 UTF-8 문자코드를 얻을 수 있습니다. 먼저 가장 앞에 1110을 붙이고, ⓐ부분의 4자리를 이어 붙여 첫 번째 바이트를 만들어 냅니다. 그 다음 가장 앞에 10을 붙이고, ⓑ부분의 6자리를 이어 붙여 두 번째 바이트를 만들어 냅니다. 마지막으로 다시 한 번 10을 붙이고, ⓒ부분을 이어 붙여서 마지막 세 번째 바이트를 만들어내면 됩니다.

이렇게 우리는 “제물포”의 UTF-8 값을 알아낼 수 있었습니다.
하지만 불행은 계속됩니다. U+FFFF 이후의 문자들(즉, 기본 다국어 평면 외의 문자들)은 몇 번 평면에 해당하는지에 대한 값이 가장 앞에 추가됩니다. 이 값이 붙고나면 역시 자리수가 늘어나서, 우리가 살펴본 이 규칙 만으로는 또다시 해결되지 않는 문제가 있습니다. 그래서 UTF-8에서는 기본 다국어 평면 외의 문자들은 4바이트로 만들어 표시합니다.
기본 다국어 평면 외의 문자는 4바이트로
1번 보조 다국어 평면부터 16번 보조 특수목적 평면까지 U+10000 ~ U+10FFFF의 문자들은 가장 앞에 몇 번 평면인지를 의미하는 번호가 붙어 있습니다. UTF-8에서는 이 영역의 문자들은 4바이트를 사용하여 표현하고 있습니다. 이 문자들을 UTF-8로 만들기 위해서는 평면 번호까지 모두 2진수로 표현해보아야 합니다.
이번 규칙을 설명하기 위한 예제로는 1번 보조 다국어 평면에 있는 재미있는 문자를 가져와 보았습니다. 유니코드에서 U+1F680 ~ U+1F6FF의 영역에는 “Transport And Map Symbols”라는 이름이 붙어 있는데, 말그대로 지도나 교통분야에서 사용하는 기호들이 모여 있습니다. 이번에 예제로 사용할 문자는 그 중에서도 U+1F686에 해당하는 TRAIN이라는 이름의 기호입니다.
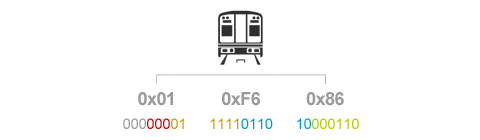
U+1F686를 2진수로 표현하면 위와 같이 될 것입니다. 이제 이렇게 구한 2진수 값을 4개 부분으로 쪼개게 됩니다.
① 1번째 바이트의 4번째 비트에서부터 3비트 … ⓐ부분
② 1번째 바이트의 뒤에서부터 2비트와 2번째 바이트의 앞에서부터 4비트 … ⓑ부분
③ 2번째 바이트의 뒤에서부터 4비트와 3번째 바이트의 앞에서부터 2비트 … ⓒ부분
④ 3번째 바이트의 뒤에서부터 6비트 … ⓓ부분
이제 4바이트의 값을 만들 차례입니다. 먼저 가장 앞에 11110을 붙이고 ⓐ부분의 3자리를 이어 붙여 첫 번째 바이트를 만들어냅니다. 다음으로 ⓐ, ⓑ, ⓒ 각 부분 앞에 10을 붙여서 나머지 3바이트를 만들어내면 됩니다.
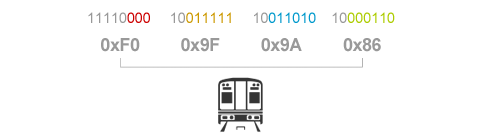
규칙에 따라 값을 만들어내고 나면, 기호 TRAIN에 해당하는 UTF-8 문자코드는 [0xF0 0x9F 0x9A 0x86]이 되는 것을 알아낼 수 있습니다. 이것으로 우리는 유니코드 값에서 UTF-8 문자코드를 만들어내는 4가지 규칙을 모두 살펴보았습니다!
가장 앞의 몇 비트로 그 바이트의 성격을 판별할 수 있는 UTF-8
이상의 4가지 규칙을 조합하면, UTF-8로 작성된 문자열은 가장 앞의 몇 개 비트를 살펴봄으로써 각 바이트의 성격을 간파할 수 있습니다.
① 어떤 바이트가 0으로 시작하면, 그 바이트는 ASCII 코드와 같은 글자입니다.
② 어떤 바이트가 110으로 시작하면, 거기서부터 2바이트가 한 글자입니다.
③ 어떤 바이트가 1110으로 시작하면, 거기서부터 3바이트가 한 글자입니다.
④ 어떤 바이트가 11110으로 시작하면, 거기서부터 4바이트가 한 글자입니다.
⑤ 마지막으로 어떤 바이트가 10으로 시작하면, 그 바이트는 어떤 글자의 중간 지점입니다.
이 규칙을 사용하면 UTF-8로 작성된 어떤 문자열이 정상적인지 잘못되었는지도 쉽게 알 수 있습니다. 이를테면 어떤 바이트가 1110으로 시작했는데, 그 뒤에 10으로 시작하는 바이트가 4개가 등장하는 것을 발견했다면, 적어도 그 근처 어디선가 값이 손실되거나 변질되었다고 단언할 수 있을 것입니다.