기본 다국어 평면과 그 외의 문자에 다른 규칙을 적용한 UTF-16
UTF-32은 유니코드 값을 그대로 32비트로 옮겨서 만든 인코딩으로, 심플하다는 장점에도 불구하고 몇 가지의 단점이 있었습니다. UTF-16는 특별한 규칙들을 통해 유니코드의 값을 변형하여 이 문제들을 해결한 인코딩입니다. UTF-16 인코딩의 규칙은 크게 기본 다국어 평면에 속하는 문자와, 그렇지 않은 문자들로 구분됩니다.
2바이트를 그대로 사용하는 기본 다국어 평면의 문자
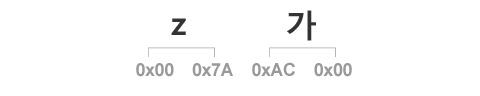
먼저 기본 다국어 평면에 속하는 문자를 UTF-16에서는 평면번호를 제외한 유니코드 값을 그대로 16비트(2바이트)로 옮겨서 사용합니다. 이를테면 영문 알파벳 중 소문자 z는 기본 다국어 평면의 0x007A 자리에 배정되어 있으므로, UTF-16에서는 [0x00 0x7A]로 표시하게 됩니다. 같은 방법으로 기본 다국어 평면의 0xAC00 자리에 배정되어 있는 한글 “가”는, UTF-16에서는 [0xAC 0x00]으로 표시할 수 있습니다.
UTF-16이 UTF-32의 용량문제를 어느 정도 해결할 수 있었던 것은 바로 기본 다국어 평면의 문자를 2바이트로 줄였기 때문입니다.
하지만 기본 다국어 평면 외의 문자를 표시할 때 UTF-16은 여전히 4바이트를 사용하며, UTF-32에 비하여 훨씬 더 복잡한 규칙을 가지고 있습니다. 이렇게 복잡한 규칙을 가지게 된 이유에 대해서는 좀더 뒤에 살펴보고, 여기서는 먼저 그 규칙이 어떤 것인지를 함께 확인해보도록 합니다.
다소 복잡한 규칙을 따르는 기본 다국어 평면 외의 문자
UTF-16에서 기본 다국어 평면 외의 문자를 표현하기 위해서는 다소 복잡한 규칙을 거쳐야 하기 때문에 설명이 곤란합니다. 설명이 곤란할 때에는 예제를 통해 살펴보는 것이 도움이 되겠지요. 이번 규칙을 설명하기 위해서 예제로 사용할 문자는 고대 그리스어에서 사용되었던 “Greek LITRA Sign”라는 문자입니다. 유니코드로는 U+10183이며, UTF-32로는 [0x00 0x01 0x01 0x83]으로 표시하는 문자입니다.
일단 UTF-16으로 표시하고자 하는 문자를 UTF-32로 먼저 표현하고, 이것을 다시 2진수로 표현하여 봅시다. Greek LITRA Sign은 아마 아래와 같은 형태가 될 것입니다.

다음으로, 아래와 같이 2진수 값을 3개 부분으로 나누어 놓는 과정이 필요합니다.
① 2번째 바이트의 뒤에서부터 5비트
② 3번째 바이트의 앞에서부터 6비트
③ 3번째 바이트의 뒤에서부터 2비트와 4번째 바이트의 8비트 전체
Greek LITRA Sign을 위의 3개 부분으로 나누어보면 아래와 같이 될 것입니다. 편의상 색상을 칠해놓았는데, 앞으로는 위 3개 부분을 아래 이미지의 색상에 따라 빨간 부분, 파란 부분, 노란 부분이라고 부르겠습니다.

이제 UTF-32를 UTF-16으로 바꾸기 위한 준비과정이 모두 끝났습니다. 이제는 아래의 5개 단계를 따라 순서대로 앞에서부터 2진수 값을 만들어 나가면, 우리가 원하는 UTF-16 인코딩 값을 얻을 수 있습니다.
① 가장 앞에서부터 110110을 붙입니다.
② 빨간 부분에서 1을 뺀 4자리의 2진수 값을 붙입니다. (이를테면 빨간 부분이 00110였다면, 1을 빼서 나온 0101 값을 이곳에 붙이면 될 것입니다.)
③ 파란 부분을 그대로 가져와 붙입니다.
④ 그 뒤에 110111을 붙입니다.
⑤ 마지막으로 노란 부분을 그대로 가져와 붙입니다.
Greek LITRA Sign 문자를 가지고 위의 5개 단계를 거치면 아래와 같이 될 것입니다. 우리가 처음에 보았던 바로 그 UTF-16 값인 [0xD8 0x00 0xDD 0x83]이 만들어져 있는 것을 확인할 수 있습니다.

문자열이 정상인지를 쉽게 확인할 수 있는 UTF-16의 규칙
도대체 기본 다국어 평면 외의 문자에는 어째서 이렇게 복잡한 규칙이 적용되어야만 했을까요. 문제의 실마리는 바로 서러게이트(Surrogate)에 있습니다.
유니코드의 기본 다국어 평면에는 사실 문자가 전혀 배정되어 있지 않은 영역이 2군데가 있습니다. 하나는 앞에서부터 여섯 비트가 110110으로 시작하는 영역으로, U+D800부터 U+DB7F까지의 영역이 여기에 해당합니다. 또 하나는 앞에서부터 여섯 비트가 110111로 시작하는 영역으로, U+DC00부터 U+DFFF까지의 영역입니다. 전자를 High Surrogate 문자영역이라고 하고, 후자를 Low Surrogate 문자영역이라고 부릅니다.
앞서 UTF-16에서는 기본 다국어 평면에 있는 문자들은 다국어 평면 번호를 떼내고 그대로 2바이트로 사용한다고 설명했습니다. 하지만 기본 다국어 평면에는 서러게이트 영역이 지정되어 있는 덕분에, 앞부터 여섯 비트이거나 110110이나 110111로 시작하는 문자가 없습니다.
따라서 우리는 UTF-16에서 앞의 여섯 비트를 확인했을 때 110110이나 110111로 시작하지 않는 경우, 거기서부터 2바이트는 무조건 기본 다국어 평면 상에 있는 문자라고 단언할 수 있습니다. 한편 앞의 여섯 비트를 확인했을 때 110110로 시작하고, 다다음 바이트가 110111로 시작한다면, 4바이트를 묶어서 기본 다국어 평면 외에 있는 문자일 것이라고 확신할 수 있습니다.
그러므로 UTF-16 문자열을 처음부터 끝까지 확인했을 때 위의 규칙에 맞지 않는 바이트가 하나라도 있다면, 그 문자열은 모종의 이유로 잘못된 문자열이라고 쉽게 판단할 수 있을 것입니다. 복잡한 규칙에도 존재의의가 있었던 것이지요.
리틀 엔디언, 빅 엔디언
UTF-16 인코딩에서 또 한 가지 알아야 하는 것이 바로 바이트 오더(Byte Order), 흔히 엔디언(Endian)이라고 하는 문제입니다. 엔디언은 컴퓨터의 메모리에 어떤 값을 저장할 때, 그 저장하는 순서를 가리키는 단어인데, 크게 리틀 엔디언과 빅 엔디언의 2가지가 있습니다.
다만 바이트 오더에 관한 주제는 이 글에서 함께 다루기에는 벅찬 긴 설명을 필요로 합니다. 따라서 바이트 오더에 관한 주제는 기회가 되는대로 별도의 글에서 다루도록 할 것입니다. 다음 편은 문자 인코딩 기초의 마지막 편으로 UTF-8 인코딩을 다루게 될 것입니다.
유니코드에 대해 뒤적거리고 있엇는데 좋은 자료 감사해요 ㅎㅎ
근데 이거 오타인가요?
“UTF-32로는 [0xD8 0x00 0xDD 0x83]으로 표시하는 문자”
UTF-16이 아닌가요?
지적에 감사드리고, 회신이 늦어서 죄송하다는 말씀도 전해드립니다. “UTF-32로는 [0x00 0x01 0x01 0x83]으로 표시하는 문자”라고 하는 것이 맞아서 글을 수정했습니다.