R은 통계적인 계산과 데이터 분석에 특화되어 있는 프로그래밍 언어입니다. 빅데이터의 대두와 함께 주목받아 그 이름이 널리 알려지게 되었지요. 새로운 언어를 공부하는 가장 좋은 방법은 책 한 권을 정독하거나, 혹은 그 언어의 공식 매뉴얼을 앞에서부터 따라가며 익히는 것입니다. 다만 이처럼 정석대로 단계 단계를 짚어가며 익힐 수 있는 여유를 가지지 못한 분들도 계실 것입니다.
이번 포스팅은 기존에 1가지 이상 익숙한 프로그래밍 언어를 가진 분들이 R의 가장 기초적인 부분을 10분 전후의 짧은 시간에 익숙해질 수 있도록 튜토리얼 형태로 쓰여졌습니다. 짧은 시간에 빠르게 R에 익숙해지기를 원하시는 분들께는 이번 포스팅이 큰 도움이 될 것입니다. 충분한 시간을 가지고 있으신 분은 이 포스팅을 살펴본 후에 R의 공식문서인 An Introduction to R을 읽어보시기를 권해드립니다.
R을 설치하고 실행해보기
R의 공식 사이트라고 볼 수 있는 곳은 The Comprehensive R Archive Network(https://cran.r-project.org/, 약칭 CRAN)입니다. CRAN의 첫 화면에는 “Download and Install R”이라는 섹션이 있어, 이곳에서 R의 설치파일을 다운로드 받으실 수 있습니다. 대부분의 분들이 처음 접하실 Windows용 R은 일반적인 소프트웨어를 설치할 때와 같이 설명 없이도 간편하게 설치할 수 있을 것입니다.
설치한 R을 실행해보시면, 위와 같이 Console 화면을 가진 RGui 화면이 표시되는 것을 볼 수 있습니다. 커서가 깜빡이는 Console 화면에서 이제 본격적인 R 코딩을 시작할 수 있습니다. Console 화면에서 구문을 입력한 후 Enter키로 줄바꿈을 하면 그 구문이 실행될 것입니다.
구문의 끝에는 다른 언어와 마찬가지로 세미콜론(;)을 붙여주어야 하나, 줄바꿈을 할 경우에는 자동으로 그 줄의 가장 끝에 세미콜론이 붙게 됩니다. 이 점은 자바스크립트와 동일합니다. R을 다루고 있는 대부분의 책이나 예제코드에서는 줄의 끝에 붙는 세미콜론은 생략하고 있습니다. 그러나 한 줄에 2개 이상의 구문을 입력하는 경우에는, 구문 사이를 세미콜론으로 구분해야 합니다.
주요 문법들
객체(변수)의 할당과 삭제
대부분의 언어에서는 이름을 붙여 어떤 값을 보관하는 가상의 공간을 흔히 변수라고 부릅니다. R에서는 이것을 객체(Object)라고 부릅니다. 이름이 객체지향 언어의 객체와 동일하기 때문에 혼동하기 쉬운 부분입니다.
객체는 미리 선언할 필요 없이 할당만 하면 바로 생성됩니다. 객체의 이름에는 문자와 숫자를 사용할 수 있으며, 첫 글자는 반드시 문자여야 합니다. 영문자가 아닌 다른 언어의 문자라도 객체의 이름에 사용하는 데에는 문제가 없습니다만, 영문자인 경우에는 대소문자를 구분한다는 점에 유의해야 합니다.
x = 13
y <- sqrt(9)
4 * x -> z어떤 객체에 값을 할당하고자 할 때, R에서도 물론 타 언어에서 흔히 지원하는 할당연산자 =를 사용할 수 있습니다. 그러나 R에서 이보다 더 널리 쓰이는 할당연산자는 <-과 ->입니다. <-는 우변의 결과를 좌변의 객체에, ->는 좌변의 결과를 우변의 객체에 대입합니다.
ls()
objects()
rm(x)현재까지 할당된 모든 객체의 이름을 확인하려면 ls() 혹은 objects() 함수를 사용합니다. 이미 할당된 객체를 삭제하기 위해서는 rm() 함수에 인자로 객체이름을 입력합니다.
자료구조
객체에는 7 가지의 자료구조를 할당할 수 있습니다.
x <- 2.7 # 실수
y <- "string" # 문자열
z <- FALSE # 논리값첫 번째는 스칼라(Scalar)입니다. 단순히 객체에 하나의 값을 할당했을 때, 바로 그 할당되는 값을 R은 스칼라라고 지칭합니다. 스칼라 값에는 실수, 문자열, 논리값(TRUE, FALSE)의 3가지 자료형이 있습니다.
v <- c(1.2, 2.7, 3.1, 4.9, 5.4)
w <- c(TRUE, FALSE, FALSE)
x <- c("a", "b", "c", "d")
y <- 1.5:4.9 # 1.5 2.5 3.5 4.5두 번째 자료구조는 벡터입니다. 벡터는 같은 자료형을 가진 스칼라 값들을 순서를 가지고 일렬로 나열한 자료구조입니다. 벡터는 함수 c()에 넣을 값들을 나열하여 생성하는 것이 일반적이나, 실수 값을 가진 벡터의 경우 시작값:종료값의 형태로도 생성할 수 있습니다. 이 경우 벡터는 시작값에서부터 종료값에 이르기 전까지 1씩 증가한 실수들로 채워질 것입니다.
matrix(
c(1, 2, 4, 8, 16, 32),
nrow=2,
ncol=3
)세 번째 자료구조는 행렬입니다. 행렬은 서로 다른 자료형을 가진 스칼라 값들을 2차원으로 나열한 자료구조입니다. 행렬은 함수 matrix(벡터, nrow=행개수, ncol=열개수)로 생성합니다.
그 외에도 자료구조에는 행렬을 3차원 이상으로 확장한 배열(Array), 다른 언어의 1차원 연관배열(Associative Array)에 해당하는 리스트(List), 같은 항목간에 그룹이 지어져 있는 팩터(Factor), 그리고 위의 모든 자료구조를 2차원 자료구조로 모두 저장할 수 있는 데이터프레임(Data Frame)이 있습니다. 이들 자료구조에 대한 대해서는 Program Creek에 한 눈에 알아볼 수 있는 좋은 요약글이 있으니 살펴보시기 바랍니다.
산술연산자
3 + 2
7 - 4
11 * 5
16 / 5
16 %/% 5 # 정수나눗셈
16 %% 5 # 나머지
3^2 # 거듭제곱R에는 타 언어에서 찾아볼 수 있는 대부분의 산술연산자가 있습니다. 다만 나눗셈의 몫을 구하는 정수나눗셈 연산자 %/%가 존재한다는 점과, 나머지를 구하는 mod 연산자가 %%라는 점은 타 언어에 비추어 볼 때 생소한 부분입니다. 또한 거듭제곱의 경우, pow() 함수를 사용하지 않고도 연산자 만으로 간단하게 연산할 수 있습니다.
v <- c(1.2, 2.7, 3.1)
v <- v + 1 # 2.2 3.7 4.1벡터나 행렬도 위처럼 산술연산자를 사용할 수 있습니다. 이 경우에는 벡터 혹은 행렬 안에 있는 모든 값에 연산을 하게 됩니다. 2개의 벡터나 행렬의 크기가 같다면 둘 사이에도 산술연산자를 사용할 수 있습니다. 반복문을 이용해야하는 다른 언어와 비교하면 문법도 간결하거니와 연산속도도 빠릅니다.
조건문과 비교 · 논리연산자
if(x == 3 || x >= 7 || x <= 1) {
x <- x+1
}
else(x != 1 && x < 3) {
x <- x-1
}타 언어에서 대부분 지원하고 있는 비교연산자 <, <=, >, >=, ==, !=는 R에서도 모두 사용할 수 있습니다. 비교연산자를 사용하면 TRUE와 FALSE 중의 하나를 결과로 얻을 수 있습니다. 이 결과는 논리연산자 ||과 &&을 통하여 OR과 AND 연산을 할 수도 있습니다.
R의 조건문은 다른 대부분의 언어들과 마찬가지로 if문과 else문으로 구성되어 있습니다. if문 안의 값이 TRUE인지 FALSE인지에 따라서 작동여부가 결정되는 것도 다른 언어와 동일합니다.
반복문
R의 반복문에는 for문과 while문이 있습니다. 다른 언어에서 찾아볼 수 있는 do-whil문은 R에서는 없습니다.
i <- 0
while(i < 10) {
i <- i + 1
}R의 while문은 다른 언어들과 같이 while(구문) { } 의 구조를 가집니다. 소괄호 안의 결과가 TRUE가 되는 한, 중괄호 안의 로직은 계속하여 반복될 것입니다.
sum <- 0
for(i in c(1, 4, 7)) {
sum <- sum + i
}한편 for문은 문법이 조금 독특한데, for(변수명 in 벡터) { } 의 구조를 가지고 있습니다. for문이 실행되면 객체 i에 벡터 안에 있는 값들이 순서대로 할당되어 들어올 것입니다. 이것은 자바스크립트의 for-in문이나 PHP의 foreach문과 유사한 측면이 있습니다.
sum <- 0
for(i in 5:15) {
if(i%%2 == 0)
{
next;
}
if(i%%10 == 0)
{
break;
}
sum <- sum + i
}반복문을 중간에 중지할 때는 다른 언어와 마찬가지로 break문을 사용합니다. 한편 반복문 내의 남은 구문을 모두 통과할 때는 다른 언어는 보통 continue문을 사용하지만, R에서는 같은 구문이 next문으로 바뀌어 있어 주의가 필요합니다.
사용자 정의 함수
f <- function(n){
sum <- 0;
for(i in 1:n){
sum <- sum + i
}
return (sum)
}
f(12)R에서도 물론 사용자가 직접 함수를 만들고, 이것을 객체에 담아 사용할 수 있습니다. 함수선언 또한 타 언어와 마찬가지로 function(인자, 인자, …) { } 구문을 따르고 있습니다.
함수실행을 마치고 값을 반환할 때는 return() 구문을 사용합니다. 많은 언어에서는 return문에서 반환할 값을 정할 때 별도로 괄호를 사용하지 않습니다만, R에서는 반드시 return문에서 반환할 값을 소괄호로 감싸야 합니다.
f <- function(n){ return (n+1) }
f(12) # 13
g <- f
g(12) # f(12)와 동일하게 작동
sum <- f
sum(12) # f(12)와 동일하게 작동함수는 한 객체에서 다른 객체로 복제하여 동일하게 사용할 수 있습니다. 이 규칙은 사용자 정의 함수 만이 아니라 내장함수에도 적용됩니다.
특별히 주의해야 하는 점은 내장함수에도 다른 함수를 할당하는 것이 가능하다는 것입니다. 위 예제에서 등장한 sum()이라는 함수는 본래 벡터나 행렬 안에 있는 요소의 총합을 구하는 내장함수입니다. 그러나 위처럼 사용자 정의 함수 f()를 할당하여 실행할 경우, f()와 동일하게 작동하는 것을 볼 수 있습니다.
기초적인 수학적 계산
sin(pi) # 1.224606e-16
log(3) # 1.098612 (자연로그)
log10(100) # 2 (상용로그)
floor(3.14) # 3 (버림)
ceiling(5.87) # 6 (올림)
round(4.65) # 5 (반올림)
sqrt(9) # 3 (제곱근)
min(c(1,5,7)) # 1 (최소값)
max(c(2,6,9)) # 9 (최대값)
mean(c(3,6,9)) # 6 (평균)
sum(c(1,2,4,7)) # 14 (합계)
sd(c(1,2,3,4)) # 1.290994 (표준편차)
runif(2, 1, 10) # 난수 2개를 벡터로 생성(1 초과 10 미만)통계분석에 사용되는 R의 특성상, 수학관련 함수들은 풍부하게 갖추고 있습니다. 위에서 소개하는 함수들은 매우 기초적인 것들 뿐입니다. 평균이나 표준편차 등과 같이 통계에서 필수불가결한 값을 구하는 함수들도 눈에 띕니다.
# (편)미분
f <- expression(2*x^3 - y*x^2 + 2*y^2 + 1)
D(f, “x”)
D(f, “y”)
# 정적분
f <- function(x) 2*x^3 - 3*x^2 + 1
integrate(f, 0, 3)R의 수학 관련 기능지원은 폭넓어서, 위처럼 미분과 정적분도 몇 줄의 소스코드로 가능합니다. 이 외에도 데이터마이닝에서 사용하는 회귀분석이라던가 군집화 알고리즘도 내장함수로 제공하고 있어 편리하게 이용할 수 있습니다.
패키지의 설치와 사용
install.packages("ggplot2")
library(ggplot2)모든 현대적인 언어들은 재사용이 가능하도록 모듈화된 패키지들을 가지고 있습니다. Node.js의 npm, Python의 pip, Java의 MAVEN처럼, R에서는 install.packages()로 패키지를 설치합니다. 설치한 패키지는 library()로 사용할 수 있습니다.
기초적인 시각화 도구
R의 시각화 도구는 커스터마이징이 까다로운 편입니다만, 단일 함수의 그래프나 단일 데이터의 분포도처럼 복잡하지 않은 시각화의 경우에는 함수 호출 만으로도 간편하게 끝이 납니다. 몇 가지 사례들을 살펴보면 아래와 같습니다.
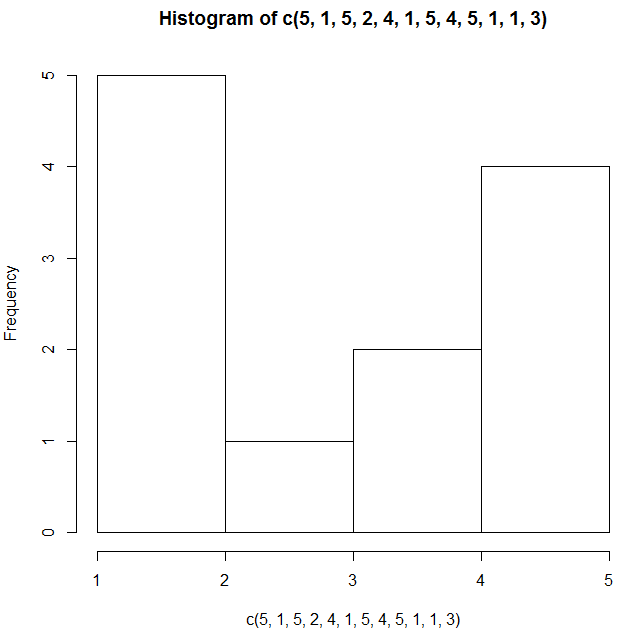
hist(c(5, 1, 5, 2, 4, 1, 5, 4, 5, 1, 1, 3))hist() 함수는 주어진 벡터나 행렬이 가진 값들의 출현빈도를 히스토그램으로 표시해줍니다. 위 소스코드는 1부터 5 사이의 정수들을 가진 벡터의 분포도를 그리는 예제입니다.
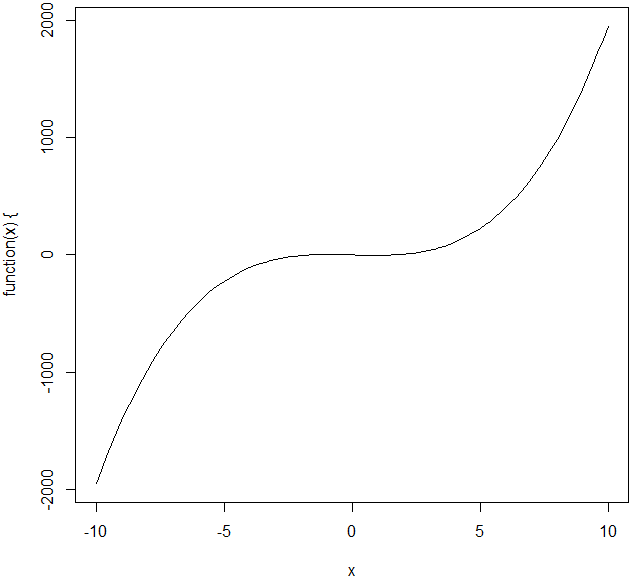
plot(function(x){ 2*x^3 - 5*x }, xlim=range(-10,10))plot() 함수는 벡터나 행렬의 분포도나 함수의 그래프를 좌표평면 위에 표시합니다. 위 소스코드는 x값이 -10부터 10까지 변할 때 주어진 3차함수의 곡선을 그리는 예제입니다.
마치며
R은 기본적으로 대부분의 개발언어와 문법상으로 유사하나 일부 매우 눈에 띄는 특이한 문법들이 있어, 일반적인 개발언어보다는 Matlab과 같은 수학적 도구에 더 가깝다는 인상을 줍니다. 또한 객체나 자료구조와 같은 핵심개념에서도 다른 언어와는 생소한 차이점이 있어 기존 언어에 익숙한 개발자의 머리 속을 혼란스럽게 하는 부분이 있습니다.
그럼에도 불구하고 다른 언어였다면 긴 로직을 작성하여 직접 구현해야 하는 수학적·통계적 기능들을 몇 번의 함수호출로 요약해버린다는 점에서 매우 강력한 도구임을 엿볼 수 있습니다. 금번 포스팅이 R에 첫 걸음을 떼는 데에 큰 도움이 되셨기를 바라겠습니다.
좋은 글 감사합니다~
jerardsong님, 감사합니다. 계속해서 좋은 글로 찾아뵙겠습니다.
최근 R에 관심가지고 공부하고 있는데
많은 도움되었습니다. 감사합니다.
san님, 덧글 감사합니다. 계속해서 좋은 글로 찾아 뵙겠습니다.
공식 사이트 보고 있었는데 생각 보다 깔끔하게 정리가 안되어서 이걸 언제 다 봐야 하나 했는데 정리 해주신 글이 정말 좋네요. 감사합니다.
R언어 스타일이 정말 직관적이고 좋네요.
kebron님, 격려에 감사드립니다. 기회가 되면 웹 언어인 PHP에서 R 연산을 할 수 있는 방법을 강구해보고 있는데, 쉽지는 않은 것 같습니다. 계속해서 좋은 글로 찾아 뵙겠습니다!
감사합니다, 기초부터 잘 알려주셔서 도움이 많이 되었어요!!
S.Han님, 덧글 감사드립니다. R에 대한 쉬운 활용사례에 대해서도 계속해서 포스팅할 수 있게 노력하겠습니다.
좋은 자료 감사합니다. 알프로그래밍을 처음 접하는 대학생인데 혹시 제가 과제를 하는데 막히는 부분이 있어서 조언좀 얻을 수 있을까요
Hyeon님 안녕하세요. 송구스럽게도 저도 R에 대해서 실무에서 깊게 관여하여 있지는 않아, 누군가에게 조언을 드릴 정도가 되지는 못하는 것 같습니다. 데이터 사이언스와 관련된 커뮤니티에서 도움을 청하시면 어떨까요? 좀더 유효한 도움을 받으실 수 있으실 것 같습니다.
좋은 정보 감사합니다.제가 궁금해서 그러는데 혹시 R로 공배수 어떻게 구하는지 아실까요..? 아시면 좀 알려주시면 감사할 것 같습니다ㅠㅜㅠ
Soo님, 안녕하세요. 방문해주셔서 감사합니다. numbers라는 패키지에 최소공배수를 구하는 LCM()이라는 함수가 있습니다. 6과 14의 최소공배수를 구하는 소스코드를 올려드리니 참고해보시기 바랍니다.
> install.packages(“numbers”)
> library(numbers)
> LCM(6,14)
[1] 42
글을 통해 몰랐던 부분을 알게 되었습니다. 감사합니다.
# (편)미분
f <- expression(2*x^3 – y*x^2 + 2*y^2 + 1)
D(f, “x”)
D(f, “y”)
# 정적분
f <- function(x) 2*x^3 – 3*x^2 + 1
integrate(f, 0, 3)
이 부분에서 x와 y의 결합함수인 f(x,y)를 x에 대해 적분하고 싶은데 혹시 어떻게 하는지 가르쳐 주실 수 있으신가요?ㅠㅠ
que님, 질문 감사드립니다.
안타깝게도 저의 전공과정에서는 미적분학 커리큘럼이 간소했던 터라, 다변수 함수의 적분에 관해서는 제가 제대로 개념을 배운 적이 없습니다. 때문에 R에서의 계산법 이전에 제 지식이 부족해서 관련된 내용을 소개해드리기 어렵습니다. 깊은 양해의 말씀 드립니다.
코딩을 배워본 사람들을 위해 R을 설명하는 아주 좋은 글이네요. 요즘 R에도 관심이 생겼는데 정말 감사합니다
박지완님, 덧글 감사드립니다. 말씀하신 바와 같이, 이 글은 코딩경험을 가진 분들께서 R을 빠르게 시작할 수 있도록 돕기 위하여 쓰여진 글입니다. 앞으로도 계속 좋은 글로 찾아뵙겠습니다.
개발자님, 저에게 이메일 주소 부탁드립니다.